

今回は、ComfyUIに標準で用意されているテンプレートワークフロー(video_wan2_2_14B_s2v)を使って、「1枚のイラストと音声ファイルからリップシンク動画を作る」という実験を行いました。
まずは基本:挨拶動画を作ってみる
手始めに、以下の素材でシンプルな動画を作ってみました。
- 画像: 生成したキャラクターのイラスト1枚
- 音声: 「今日も一日お疲れ様なのじゃ」という短いセリフの音声ファイル
結果: 音声と口の動きが合っています。これは非常にうまくいきました。
「日々の挨拶動画」くらいならすぐに量産できそうです。

ここで気になったことは動画の長さです。
何も考えずにとりあえず生成した見たのですが、生成された動画の長さが14.4375秒でした。
これがデフォルト値みたいです。
問題はこれが設定値をかえるだけで長くしたり短くしたり出来ない事です(多少は出来る)
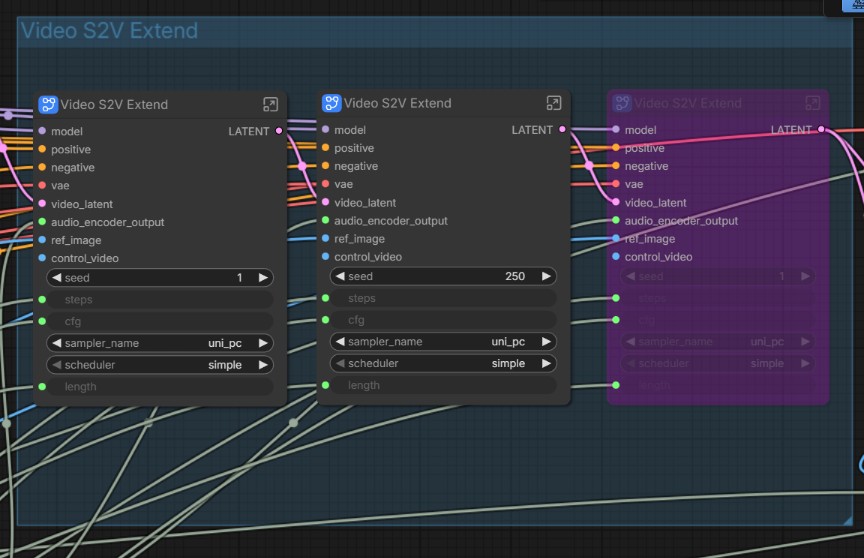
図の「VideoS2VExtend」というノードを複数重ねて動画にしているみたいです。
1つにつき(ChunkLength / fps)秒で、デフォルトではChunkLengthは77、fpsは16です。
これが3つあるので(ChunkLength / fps)×3 で 14.4375秒 なのです。
ChunkLengthの値はワークフローの注意書きに以下のように書かれていたので77固定です。
WAN2.2S2Vの公式コードでは、77がデフォルトの長さです。このモデルでは少なくとも73フレームが必要です。値を高く設定しすぎると、メモリ不足の問題が発生する可能性があります。
そのため、77のままで問題ありません
なので、動画の長さを変更できる場所は、fpsの値とVideoS2VExtendの数になってきます。
ちょっと面倒なので、デフォルトの14.4375秒で進めていきます。
歌わせてみる
次に、以前AIで作った「オリジナル楽曲」を使って、MV風の動画を作ってみることにしました。
- 画像: 1枚のイラスト
- 音声: 歌入りの楽曲ファイル(出だしからすぐ歌が始まるタイプ)
結果: 生成された動画を見ると、歌詞に合わせて口が動いており、一見すると完璧なリップシンク動画に見えました。 しかし、ここでふと昔の記憶が蘇りました。以前、別のリップシンクツールを使った時に**「ボーカル以外の音(ドラムやベース)にも反応して口が動いてしまう」**という現象があったのです。

「もしかして、今回もうまくいったように見えているだけで、実は全部の音に反応しているのでは?」
検証:イントロのある曲で試す
疑念を晴らすため、あえて意地悪なテストを行いました。
- 音声: 「歌 → 長い間奏(イントロ) → 歌」 という構成の楽曲
もしAIが賢く「人の声」だけを認識しているなら、間奏部分は口を閉じるはずです。
結果: ダメでした。 予想通り、キャラクターはギターのイントロに合わせて楽しそうに口をパクパクさせていました。 これでは「歌っている」のではなく「音に合わせて顎が振動している」だけです。これではMVとしては使えません。

課題:音声とBGMの分離が必要
原因は明白です。今のワークフローでは、AIに楽曲ファイルそのものを渡しているため、AIは**「この音の波形に合わせて口を動かせばいいんだな」**と判断し、楽器の音も全部拾ってしまっているのです。
これを解決するには、ComfyUIの中で**「楽曲からボーカル(人の声)だけを抜き出す」**という処理が必要になります。
救世主:音源分離ワークフロー
どうやってComfyUI内で音を分離すればいいのか悩んでいたところ、X(旧Twitter)の相互フォロワーさんであるSakuraVividさん(https://x.com/SakuraVisionLab)から助け舟が出ました。
「音声を分離するワークフローがあるよ」と、URLを教えていただいたのです。
https://github.com/kijai/ComfyUI-MelBandRoFormer/tree/main
URLのワークフローとモデルをダウンロードして、まずは音声とその他の音が分離されるか動作チェックしました。
見事に分離されました!
解決:ワークフローの合体
教えてもらった分離の仕組みを、先ほどまで使っていたWan2.2の動画生成ワークフローに組み込みました。
接続は以下の通り。リップシンク動画生成は音声ファイルを使い最終的な動画は元の音楽ファイルを使うという設定方法です。
・「音声を読み込む」 オーディオ → 「Mel-Band RoFormer Sa…」 audio
・「音声を読み込む」 オーディオ → 「動画を作成」 オーディオ
・「Mel-Band RoFormer Sa…」 vocals → 「オーディオエンコーダーエンコード」 オーディオ
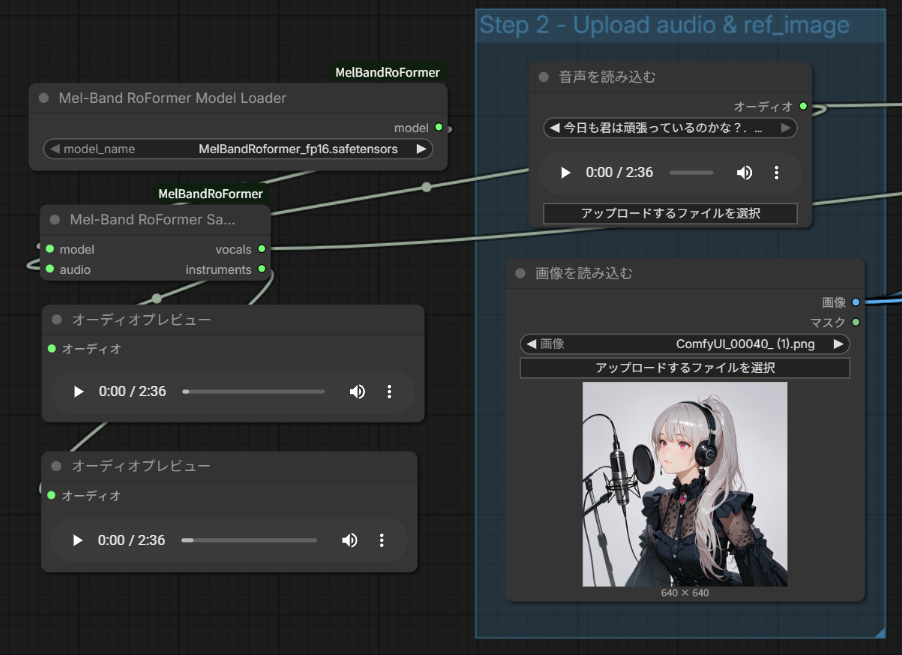
- 楽曲読み込み
- 音源分離ノード: ここで「Vocal(声)」と「Instrumental(楽器)」に分ける。
- リップシンク入力: Wan2.2への指示には、分離した**「Vocal」だけ**を繋ぐ。
- 動画生成
最終結果: 生成された動画を確認すると、音声ファイルの所だけ口が動いていたので成功です!
注意点として、動画のプロンプトに「歌っている」などといれると、リップシンクの機能関係なしに口パクをしてしまう場合があるという事です。
なので、今回はあえてプロンプトに「Women keep their mouths shut and don’t sing.」と入れました。
そうすると、音声の無いところでは口パクしません。音声の有るところはリップシンク機能の方が上位なのかプロンプトを無視してリップシンクしてくれました。
まとめ
1枚の絵からリップシンク動画を作る際、セリフ(肉声のみ)ならそのままで大丈夫ですが、「音楽(BGM入り)」を扱う場合は、必ず「音源分離(Vocal Separation)」の工程を挟む必要があります。
これをやらないと、ドラムのバスドラムに合わせて口がパクパクする奇妙な動画になってしまいます。 ComfyUIはこういった「特定の機能(今回は音源分離)」をパズルのように組み込めるのが最大の強みですね。
教えてくださったSakuraVividさん(https://x.com/SakuraVisionLab)に感謝です。
追記(2026/02/18)
このワークフローを使って1曲フル(3分36秒)を1回の生成で出来るか試してみました。
結果は失敗に終わりました。VAEデコードでエラーが起きました。
これの生成(失敗)に5~6時間はかかったと思います^^;
なのでこの方法はあまりお勧めできません。


コメント