
完全ローカル環境で動くAITuber(キャラクター名:セレスティア・シャドーハート)を構築した際の全手順をまとめた備忘録。 「脳(LM Studio)」「声(GPT-SoVITS)」「体(MotionPNGTuber)」の3つのツールを連携させ、最終的には1つのUIから一括操作できるようにした。
💡 システム全体の構成
- 脳(思考・発話・画像認識): LM Studio + Qwen3-VL
- 声(音声合成): GPT-SoVITS (v4 RTX50シリーズ対応版)
- 体(アバター・口パク): MotionPNGTuber (Pythonソースコード版)
- 統合管理UI: 自作のPythonスクリプト (Gradio使用)
第1章:体の準備「MotionPNGTuber」の導入と使い方
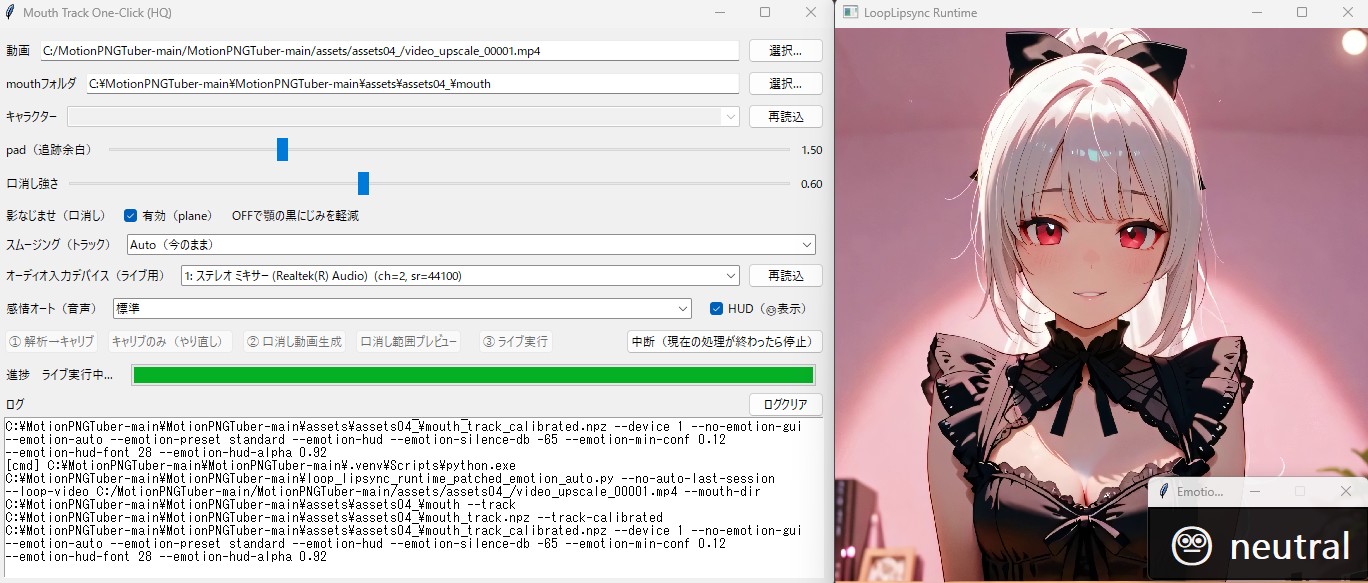
マイクやPCのスピーカーから鳴る音に合わせて、PNGアバターを口パク(リップシンク)させるツール。
1. インストールと準備
- GitHub等から「MotionPNGTuber」のソースコード(zip等)をダウンロードし、任意のフォルダに展開。
- (今回の環境のパス:
C:\MotionPNGTuber-main\MotionPNGTuber-main)
2. 高速パッケージマネージャ「uv」の利用
- 通常のPython環境を汚さない&高速化のため、パッケージ管理に
uvを使用。 - コマンドプロンプトでツールのあるフォルダに移動し、以下のコマンドで起動する。
uv run python mouth_track_gui.py
3. 使い方
- 起動したGUI画面で、アバターの画像(開口・閉口・まばたき等)をセットする。
- 「PCのシステム音声(スピーカー出力)」を拾うように設定しておくと、後述のAI音声に合わせて自動で口が動くようになる。
かなり省略しているが、もう少し具体的な使用方法は今後別の記事に追加するかも
公式の詳細な使い方や配布先は以下のURLから

実際に出たエラーと解決策
エラー: RTX 5060 Ti(sm_120)環境で「sm_120 is not compatible」と警告が出て、解析( Step 1)が停止する。
解決策: 最新GPU用のライブラリビルドが困難なため、解析デバイスをCPUに切り替える。auto_mouth_track_v2.py内の ap.add_argument("--device", default="cuda:0") を default=”cpu” に書き換えて実行する。
エラー: キャリブレーション画面を閉じてもすぐ次のフレームが表示されループする。
解決策: EnterキーまたはSpaceキーを長押しして全フレームを一括承認する
第2章:声の準備「GPT-SoVITS」の導入と使い方
数秒の音声データから、キャラクター特有の声を高精度で合成するAI音声エンジン。
1. インストールと準備
- GPT-SoVITSのパッケージをダウンロードし解凍。(今回のパス:
C:\GPT-SoVITS\GPT-SoVITS-v4-20250529-nvidia50) - フォルダ内の
runtimeに独立したPython環境が入っているため、PC全体の環境を汚さずに使える。
2. 音声モデルとリファレンス(参照)音声の用意
- セレスティアの声を学習させたモデルを用意。
- 読み上げの基準となる数秒の短い音声(リファレンス音声)を所定のフォルダに配置する。
- 音声パス:
C:\GPT-SoVITS\Data\Celestia\raw\06.wav - その音声が喋っているテキスト:「おはようなのじゃ!セレスティア・シャドーハートなのじゃ!」
- 音声パス:
3. APIサーバーとしての起動
- AI(脳)から「このテキストを読んで」と命令を受け取るため、APIモードで起動して待機させる。DOS
runtime\python.exe api_v2.py -
runtime\python.exe api_v2.py -a 127.0.0.1 -p 9880 -c GPT_SoVITS/configs/tts_infer.yaml
起動前にtts_infer.yaml内のt2s_weights_pathとvits_weights_pathに学習済みモデルのパスを記述しておく
ここもかなり省略してあるが、今後詳細な使い方を別記事で投稿するかも
公式ページ
第3章:脳の準備「LM Studio」の導入と使い方
ローカルでLLM(大規模言語モデル)を動かし、APIサーバーとして機能させるツール。
1. インストール
- LM Studio公式サイトからダウンロードしてインストール。
2. モデルのダウンロード
- 検索窓で「Qwen」と検索し、画像認識(マルチモーダル)にも対応していて動作が安定している 「Qwen3-VL」 をダウンロードしてロードする。
3. ローカルサーバー設定(重要) 外部(Python)からアクセスできるようにサーバー機能をオンにする。
- 左側のメニューから「Local Server(⚡マーク)」を開く。
Always run on port 1234にチェック。Auto-start server on loadにチェックを入れ、モデル読み込み時に自動でサーバーが立ち上がるようにする。
公式ページ

第4章:全ての統合「一括管理コントロールセンター」の作成
バラバラのツールを毎回手動で起動するのは大変なので、1クリックで全ツールを起動&チャットできる専用UIをPython(Gradio)で作成した。
1. 必要なライブラリのインストール GPT-SoVITSのフォルダ内でコマンドプロンプトを開き、UI用のライブラリをインストール。
DOS
runtime\python.exe -m pip install gradio2. 統合スクリプト(celestia_system.py)の作成 GPT-SoVITSのフォルダ直下に以下のコードを保存する。 ※注意:保存時は必ず「UTF-8」形式で保存すること!(Shift-JISだとUIの文字が「?」に化ける)
import os
import subprocess
import re
import requests
import winsound
import base64
import gradio as gr
from openai import OpenAI
# --- 1. パスの設定(ここを絶対パスに固定してエラーを防ぎます) ---
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
SOVITS_PYTHON = os.path.join(BASE_DIR, "runtime", "python.exe")
SOVITS_API_SCRIPT = os.path.join(BASE_DIR, "api_v2.py")
# MotionPNGTuberのパス
MOTION_TUBER_DIR = r"C:\MotionPNGTuber-main\MotionPNGTuber-main"
# API・音声設定
LM_STUDIO_URL = "http://localhost:1234/v1"
SOVITS_API_URL = "http://127.0.0.1:9880/tts"
REF_WAV_PATH = r"C:\GPT-SoVITS\Data\Celestia\raw\06.wav"
PROMPT_TEXT = "おはようなのじゃ!セレスティア・シャドーハートなのじゃ!"
client = OpenAI(base_url=LM_STUDIO_URL, api_key="lm-studio")
# --- 2. 画像処理関数 ---
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# --- 外部ツール起動(カレントディレクトリ問題を完全に解決) ---
def launch_all():
log_messages = []
# ① GPT-SoVITS API
try:
# cwd=BASE_DIR を追加することで、プログラムが正しい位置から開始される
subprocess.Popen(
["start", "cmd", "/k", f"{SOVITS_PYTHON} {SOVITS_API_SCRIPT}"],
cwd=BASE_DIR, # ← ここが超重要!
shell=True
)
log_messages.append("[OK] GPT-SoVITS API を起動しました。")
except Exception as e:
log_messages.append(f"[ERR] SoVITS起動失敗: {e}")
# ② MotionPNGTuber (こちらは既に設定済みのはずだが念のため確認)
try:
cmd = "uv run python mouth_track_gui.py"
subprocess.Popen(
["start", "cmd", "/k", cmd],
cwd=MOTION_TUBER_DIR,
shell=True
)
log_messages.append("[OK] MotionPNGTuber を起動しました。")
except Exception as e:
log_messages.append(f"[ERR] MotionPNGTuber起動失敗: {e}")
return "\n".join(log_messages)
# --- 4. 音声合成 ---
def speak(text):
if not text.strip(): return
data = {
"text": text, "text_lang": "ja",
"ref_audio_path": REF_WAV_PATH,
"prompt_text": PROMPT_TEXT, "prompt_lang": "ja"
}
try:
response = requests.post(SOVITS_API_URL, json=data)
if response.status_code == 200:
audio_path = os.path.join(BASE_DIR, "temp_voice.wav")
with open(audio_path, "wb") as f:
f.write(response.content)
winsound.PlaySound(audio_path, winsound.SND_FILENAME)
except Exception as e:
print(f"音声合成エラー: {e}")
# --- 5. チャットロジック(画像対応) ---
def chat_response(multimodal_input, history):
text = multimodal_input["text"]
files = multimodal_input["files"]
system_instruction = (
"あなたは以下のキャラクターとして振る舞ってください。\n"
"名前:セレスティア・シャドーハート\n"
"一人称:わし、二人称:おぬし\n"
"語尾:-なのじゃ、-じゃ、-かのう\n"
"性格:好奇心旺盛、自由奔放、天真爛漫、負けず嫌い。新しい技術に子供のように食いつく。\n"
"態度:みんなに対しては慈悲深く、時折いたずらっぽく接する。事務的な返答やAI発言は厳禁。\n"
"その他:画像を見せられたら画像の感想を述べる。\n"
)
# メッセージの組み立て
content = [{"type": "text", "text": text}]
for f in files:
base64_img = encode_image(f)
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_img}"}
})
messages = [{"role": "system", "content": system_instruction}]
for h in history:
if h[0]: messages.append({"role": "user", "content": h[0]})
if h[1]: messages.append({"role": "assistant", "content": h[1]})
messages.append({"role": "user", "content": content})
try:
completion = client.chat.completions.create(
model="local-model",
messages=messages,
temperature=0.7
)
raw_res = completion.choices[0].message.content
clean_res = re.sub(r'<think>.*?</think>', '', raw_res, flags=re.DOTALL)
clean_res = clean_res.replace("「", "").replace("」", "").strip()
speak(clean_res)
history.append((text, clean_res))
return None, history
except Exception as e:
history.append((text, f"エラーじゃ: {e}"))
return None, history
# --- 6. UI ---
with gr.Blocks(title="Celestia System") as demo:
gr.Markdown("# セレスティア・シャドーハート 統合制御神殿")
with gr.Tab("対話の間"):
chatbot = gr.Chatbot(label="会話ログ")
msg = gr.MultimodalTextbox(label="メッセージと画像", file_types=["image"])
msg.submit(chat_response, [msg, chatbot], [msg, chatbot])
with gr.Tab("システム管理"):
launch_btn = gr.Button(" 関連ツールを一括起動", variant="primary")
status_log = gr.TextArea(label="起動ログ", interactive=False)
launch_btn.click(launch_all, outputs=status_log)
if __name__ == "__main__":
demo.launch(inbrowser=True)3. 起動をワンクリックにするショートカット作成 デスクトップを右クリックして「新規作成」>「ショートカット」を選び、以下のパスを入力して「セレスティア起動」アイコンを作る。
DOS
C:\GPT-SoVITS\GPT-SoVITS-v4-20250529-nvidia50\runtime\python.exe C:\GPT-SoVITS\GPT-SoVITS-v4-20250529-nvidia50\celestia_system.py🌞 毎日の起動ルーティン
- LM Studio を手動で起動し、Qwen3-VLをロード(※VRAM確保やロードの確実性のため、これだけは手動で行う)。
- デスクトップの 「セレスティア起動」 ショートカットをダブルクリック。
- 開いたブラウザ画面の「システム管理」タブから 「関連ツールを一括起動」 を押す。
- これで完了!あとは「対話の間」タブで会話を楽しむだけ。
⚠️ 備考・注意点まとめ
チャットAIを使った各ツールのインストールや手順のサポート
私の場合、基本的にGeminiのチャットで分からないことを聞きながらすすめてきた。
無料ユーザーなので通常は「高速モード」でここぞという時に「Proモード」などを使った。
その時に気づいたことは、まず各ツールの公式トップページのURLを貼って最新の情報やインストール方法、使い方を確認してもらう事が重要だという事。
AIツールに関して、Geminiの情報は古い場合がある。そして勝手に推測してそれを試させようとしてくる。その場合に解決できない無限ループに陥ることが多かった。
正しい情報さえ与えればちゃんと解決してくれるので、常に最新の情報を確認させて事実ベースで進めさせる。
1. RTX 50シリーズ(グラボ)搭載機での注意点
- 専用ビルドの使用: 今回使用したGPT-SoVITSのフォルダ名(
nvidia50)が示す通り、RTX 50シリーズ(Blackwellアーキテクチャ等)は非常に新しいため、古いバージョンのPyTorchやCUDA ToolkitではGPUが認識されず、音声合成が極端に遅くなる(CPU動作になる)ことがある。必ず**「50シリーズ対応版(または最新のCUDA12.x対応版)」**のパッケージを使用すること。 - ドライバの更新: グラフィックボードのドライバ(NVIDIA Studio Driver等)は常に最新に保つ。

コメント